Recherche de fichiers en double¶
Dans ce contexte, les fichiers en double sont des fichiers qui semblent exister plus d’une fois. De tels fichiers redondants augmentent inutilement l’espace alloué de vos disques.
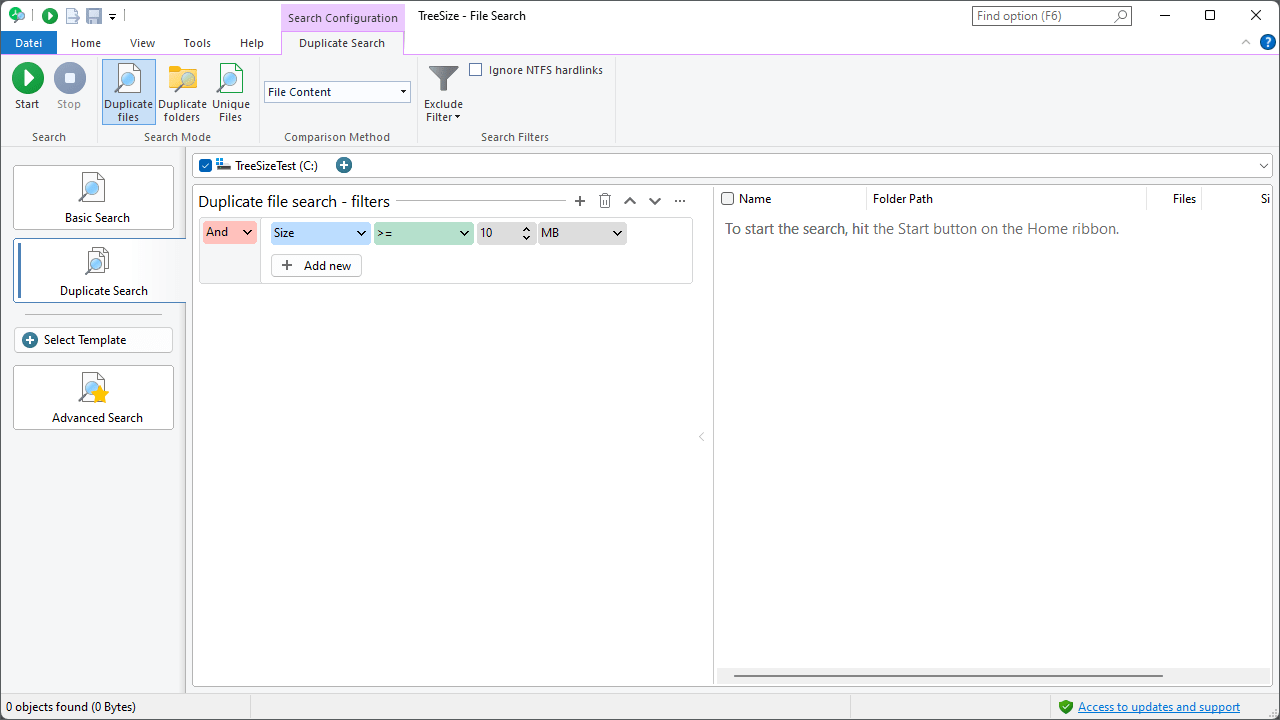
Onglet de contexte¶
Mode de recherche¶
Sélectionnez l’un des trois modes de recherche de doublons. Vous pouvez rechercher des fichiers en double, des dossiers en double ou des fichiers qui n’ont pas de doublons.
Fichiers dupliqués¶
Recherche de fichiers qui sont des doublons les uns des autres, en utilisant la méthode de comparaison sélectionnée.
Dossiers en double¶
Recherche de dossiers qui sont des doublons les uns des autres. Deux dossiers sont considérés comme des doublons s’ils contiennent le même nombre de sous-dossiers et de fichiers. Ces sous-dossiers et fichiers doivent également être égaux les uns aux autres, en ce qui concerne la méthode de comparaison sélectionnée.
Fichiers uniques¶
Ce paramètre recherche des fichiers qui n’ont pas de doublons dans les chemins de recherche sélectionnés.
Méthode de comparaison¶
Définit quels critères doivent être utilisés pour identifier les fichiers comme doublons. Voici une liste des stratégies disponibles :
Contenu du fichier¶
Cette option utilise par défaut des sommes de contrôle MD5 pour la comparaison.
Lors de l’utilisation de cette méthode, une valeur de hachage est calculée en fonction du contenu de chaque fichier. Les fichiers ayant le même contenu auront la même valeur de hachage, les fichiers ayant un contenu différent auront presque certainement des valeurs différentes. Les fichiers vides sont ignorés, car il n’y a pas de contenu à comparer.
C’est plus précis que de comparer les fichiers par leur nom, taille et date, mais c’est aussi beaucoup plus lent.
Dans les options de recherche de fichiers, il est possible d’ajuster cette méthode pour utiliser des hachages SHA256 à la place. L’algorithme SHA256 réduit encore le risque statistique de collisions de hachage par rapport à MD5, mais il est également significativement plus lent. Cette option n’est visible que lors de l’utilisation du mode d’application expert.
Taille, Nom et Date¶
Sélectionnez cette option pour identifier les fichiers en double en recherchant des noms, des tailles et des dates de dernière modification identiques.
C’est beaucoup plus rapide que d’utiliser des sommes de contrôle pour indiquer des doublons, mais c’est également moins précis.
Nom et taille¶
Sélectionnez cette option pour identifier les fichiers en double en recherchant des noms et des tailles identiques.
Égal au tout premier critère de comparaison, mais sans tenir compte de l’horodatage « dernier modifié » des fichiers.
Cela est utile dans le cas où des fichiers ont été déplacés d’un emplacement à un autre, ce qui pourrait modifier cet horodatage.
Nom¶
Sélectionnez cette option pour trouver tous les fichiers avec des noms de fichiers identiques.
Ce type de comparaison peut être utile lorsque vous recherchez des copies indésirables (par exemple, des documents qui ont été copiés et modifiés localement).
Nom sans extension¶
Sélectionnez cette option pour détecter les fichiers avec des noms identiques, sans tenir compte de l’extension de fichier.
Cela peut être intéressant si vous recherchez des fichiers de sauvegarde dupliqués ou par exemple des fichiers de données brutes et des fichiers d’image ou vidéo compactés (« MyPhoto.bmp » - « MyPhoto.png »).
Taille et Date¶
Compare les fichiers selon leurs valeurs de taille et de date. Cela permet une recherche plus rapide, mais donc moins précise, de fichiers dupliqués avec des noms différents. Les copies accidentelles avec des noms tels que « Copie de … » peuvent être identifiées rapidement en utilisant cette méthode.
Taille uniquement¶
Sélectionnez cette option pour trouver tous les fichiers de taille égale.
Filtres de recherche¶
Options supplémentaires pour personnaliser la recherche de fichiers dupliqués :
Filtre d’exclusion¶
Permet d’activer, de désactiver ou de personnaliser les filtres d’exclusion globaux pour cette recherche.
En restreignant la recherche de doublons à une préselection spécifique de fichiers, vous pouvez éviter de lister des fichiers de certains répertoires (par exemple, vos répertoires système locaux) comme doublons. De plus, cette option réduira le nombre de fichiers à comparer, ce qui améliore la vitesse de la recherche.
Ignorer les liens durs NTFS¶
Si cette option est activée, les liens physiques ne sont pas considérés comme des fichiers en double. Remarque : les liens physiques NTFS n’allouent pas de mémoire. Par conséquent, les supprimer ne libère pas de mémoire supplémentaire. De plus, TreeSize utilise des liens physiques pour la déduplication.
Dédupliquer¶
Utilisez le bouton « Opérations > Dédupliquer » pour remplacer tous les fichiers en double cochés par des liens physiques NTFS (Comment fonctionne la déduplication ?)
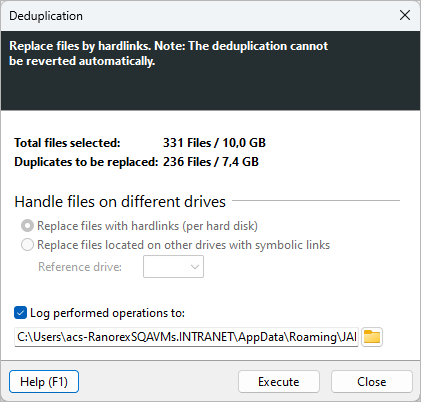
Options¶
Choisissez l’un des trois types de liens à utiliser pour remplacer les doublons :
Remplacer par des liens solides¶
Il s’agit de l’option par défaut. Les liens en dur sont une caractéristique du système de fichiers NTFS. Ils permettent à plusieurs noms de fichiers sur la même partition de faire référence au même enregistrement dans le système de fichiers. Tous les liens durs sont égaux, il n’y a donc pas d’original. Les modifications apportées par le biais d’un lien dur affectent les mêmes données sous-jacentes. La suppression d’un lien dur n’affecte pas les autres, sauf s’il s’agit du dernier.
Remplacer par des liens symboliques¶
Les liens symboliques sont des objets spéciaux du système de fichiers qui font référence à un autre fichier en stockant son chemin d’accès. Contrairement aux liens matériels, ils peuvent s’étendre sur différentes partitions, lecteurs et emplacements réseau. Si le fichier cible est déplacé ou supprimé, le lien symbolique devient invalide.
Comparer avec l’instantané¶
Les raccourcis sont des fichiers ordinaires créés par Windows avec l’extension .lnk qui stockent des métadonnées sur un fichier cible. Ils peuvent pointer vers à peu près n’importe quoi, mais tous les programmes ne peuvent pas gérer les raccourcis. Comme les liens symboliques, le raccourci est rompu lorsque le fichier cible est déplacé ou supprimé.
Cliquez sur l’icône ? à côté de chaque option pour obtenir des informations supplémentaires.
Journalisation¶
Activez l’option « Enregistrer les opérations effectuées dans : » pour enregistrer toutes les actions dans un fichier journal. Saisissez un chemin d’accès au fichier dans le champ de texte ou utilisez le bouton Parcourir pour choisir un emplacement.
Statistiques sur les types de fichiers¶
La partie droite de la boîte de dialogue affiche des statistiques et un aperçu des opérations planifiées.
En haut, vous pouvez voir :
Nombre d’éléments vérifiés indique le nombre total de fichiers sélectionnés pour la déduplication.
Taille totale des éléments contrôlés indique la taille combinée des fichiers contrôlés.
Sous les statistiques se trouve une liste de prévisualisation avec les colonnes suivantes :
L’opération montre le rôle de chaque fichier. Le fichier cible (maître) est marqué d’une icône en forme d’étoile et étiqueté « Cible pour lien dur ». Les fichiers en double qui seront remplacés sont marqués d’une icône de lien et étiquetés « Remplacer par un lien dur » (ou l’étiquette correspondante pour les liens symboliques ou les raccourcis, en fonction de l’option sélectionnée).
Nom indique le nom du fichier.
Chemin d’accès indique le chemin d’accès au fichier.