Duplicate file search¶
In this context, duplicate files are files which seem to exist more than once. Such redundant files increase the allocated space of your disks unnecessarily.
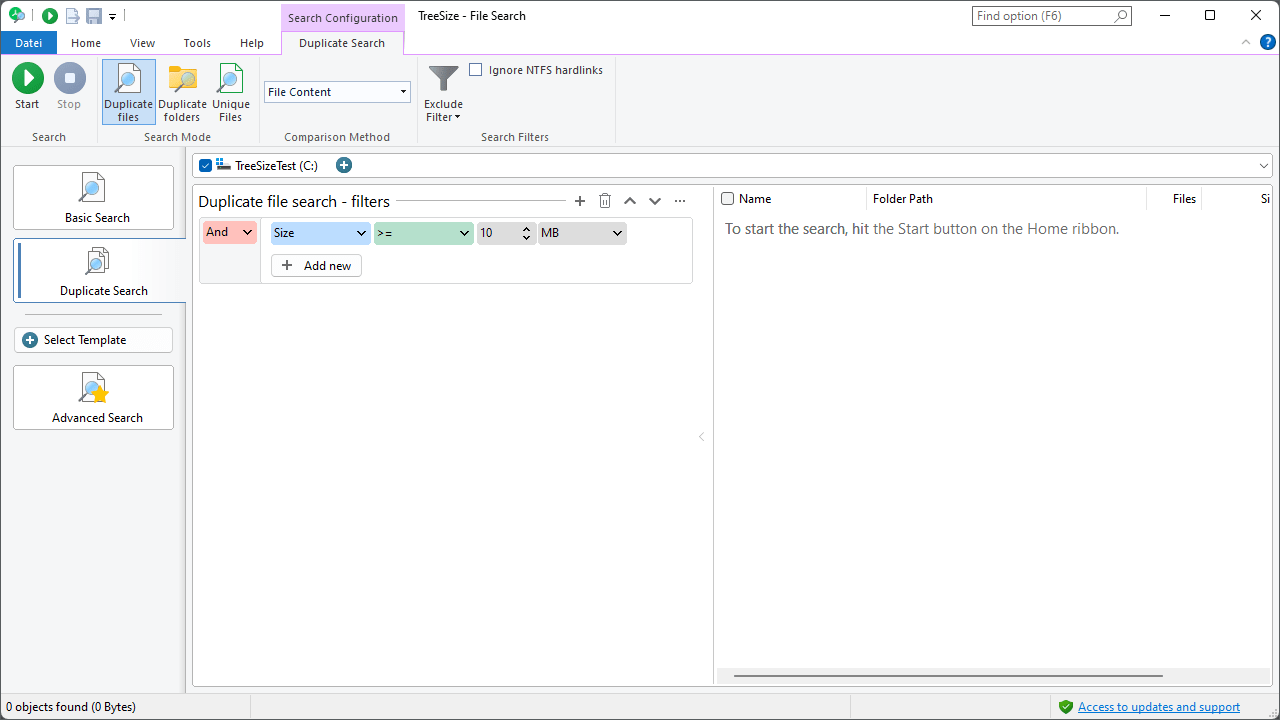
Context tab¶
Search Mode¶
Select one of three modes of the duplicates search. You can search for duplicate files, duplicate folders, or files that do not have any duplicates.
Duplicate Files¶
Searches for files that are duplicates of each other, using the selected comparison method.
Duplicate Folders¶
Searches for folders that are duplicates of each other. Two folders are considered duplicates, if they contain the same amount of subfolders and files. These subfolders and files also have to be equal to each other, in regards to the selected comparison method.
Unique Files¶
This setting searches for files that do not have any duplicates across the selected search paths.
Comparison method¶
Defines which criteria should be used to identify files as duplicates. Here is a list of the available strategies:
File Content¶
This option uses MD5 checksums for comparison by default.
When using this method, a so called hash value is calculated based on the contents of each file. Files with the same content will have the same hash value, files with different content will almost certainly have different values. Empty files are ignored, since there is no content to compare.
This is more accurate than comparing files by their name, size and date but it is also much slower.
Within the file search options, it is possible to adjust this method to use SHA256 hashes instead. The SHA256 algorithm further reduces the statistical risk of hash collisions compared to MD5 but it is also significantly slower. This option is only visible when using the expert application mode.
Size, Name and Date¶
Select this option to identify duplicate files by looking for equal names, sizes and last change dates.
This is much faster than using check sums to indicate duplicates, but it is also less accurate.
Name and Size¶
Select this option to identify duplicate files by looking for equal names and sizes.
Equal to the very first compare criteria, but without regarding the “last modified” time stamp of the files.
This is helpful in case files had been moved from one location to another, which might modify this time stamp.
Name¶
Select this option to find all files with equal file names.
This compare type can be helpful when you are searching for undesired copies (e.g. documents which have been copied and modified locally).
Name without Extension¶
Select this option to detect files with equal names, without regarding the file extension.
This can be interesting in case you are searching for duplicated backup files or e.g. row-data and compact image or video files (“MyPhoto.bmp” - “MyPhoto.png”).
Size and Date¶
Compares files according to their size and date values. This allows for a faster, but therefore less accurate search for duplicate files with different names. Accidental copies with names such as “Copy of …” can be identified quickly, using this method.
Size only¶
Select this option to find all files with equal size.
Search Filters¶
Additional options to customize the duplicate file search:
Exclude filter¶
Allows to activate, deactivate or customize the global exclude filters for this search.
By restricting the duplicate search to a specific preselection of files, you can prevent listing files of certain directories (e.g. your local system directories) as duplicates. Additionally, this option will reduce the number of files to compare, which improves the speed of the search.
Ignore NTFS hardlinks¶
If this option is activated, hardlinks are not regarded as file duplicates. Note: NTFS hardlinks do not allocate memory. Therefore, deleting them does not make additional memory available. In addition, TreeSize uses hard links for deduplication.
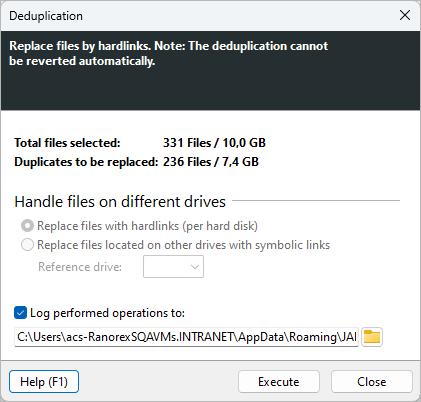
Deduplicate¶
Click “Operations > Deduplicate” to open the deduplication dialog. This dialog lets you replace all but one checked duplicate file by links. See Understanding the deduplication process for background on how the deduplication process works.
Options¶
Choose one of three link types to use when replacing duplicates:
Replace with hardlinks¶
This is the default option. Hardlinks are a feature of the file system NTFS. They allow multiple filenames on the same partition to reference the same record in the file system. All hardlinks are equal, so there is no original. Changes made through a hardlink affect the same underlying data. Deleting one hardlink does not affect the others, unless it is the last one.
Replace with symbolic links¶
Symbolic links are special file system objects that reference another file by storing its path. Unlike hardlinks they can span over different partitions, drives and network locations. If the target file is moved or deleted, the symlink becomes invalid.
Replace with shortcuts¶
Shortcuts are regular files created by Windows with the .lnk extension that store metadata about a target file. They are able to point to pretty much anything, but not all programs can handle shortcuts. Like symbolic links, when the target file is moved or deleted the shortcut is broken.
Click the ? icon next to each option for additional information.
Logging¶
Enable “Log performed operations to:” to record all actions to a log file. Enter a file path in the text field or use the browse button to choose a location.
Statistics and Preview¶
The right side of the dialog shows statistics and a preview of the planned operations.
At the top you can see:
Number of checked items shows the total number of files selected for deduplication.
Total size of checked items shows the combined size of the checked files.
Below the statistics is a preview list with the following columns:
Operation shows the role of each file. The target file (master) is marked with a star icon and labeled “Target for hard link”. Duplicate files that will be replaced are marked with a link icon and labeled “Replace with hard link” (or the corresponding label for symbolic links or shortcuts, depending on the selected option).
Name shows the file name.
Path shows the file path.